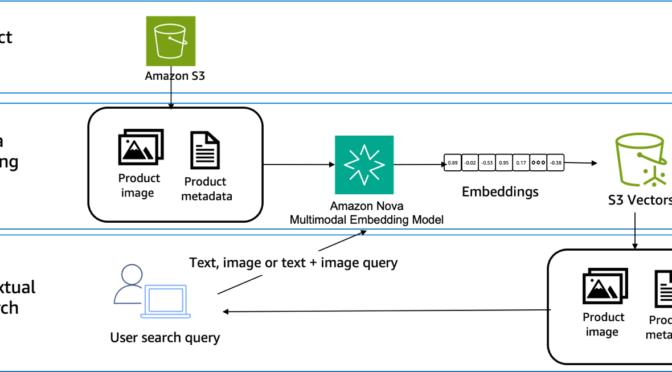
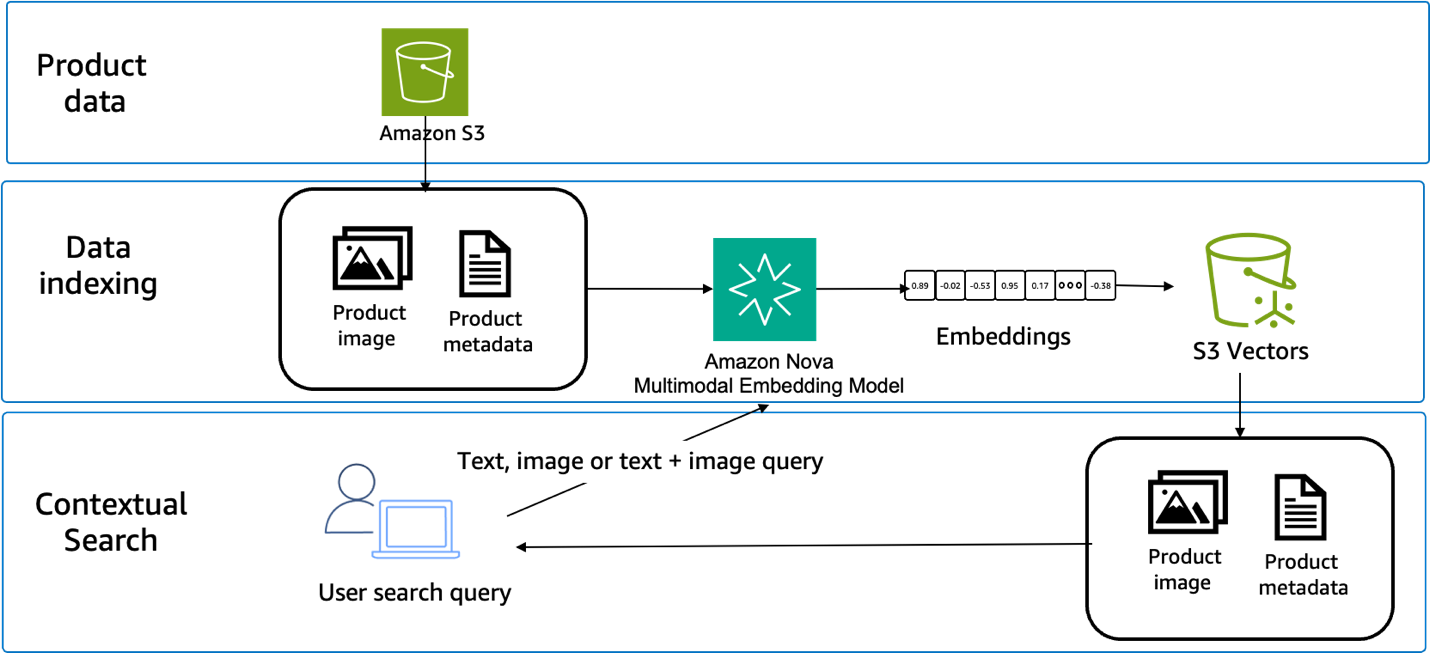
Today, we’re announcing the general availability of Amazon Elastic Compute Cloud (Amazon EC2) G7e instances that deliver cost-effective performance for generative AI inference workloads and the highest performance for graphics workloads.
G7e instances are accelerated by the NVIDIA RTX PRO 6000 Blackwell Server Edition GPUs and are well suited for a broad range of GPU-enabled workloads including spatial computing and scientific computing workloads. G7e instances deliver up to 2.3 times inference performance compared to G6e instances.
Improvements made compared to predecessors:
- NVIDIA RTX PRO 6000 Blackwell GPUs — NVIDIA RTX PRO 6000 Blackwell Server Edition GPUs offer two times the GPU memory and 1.85 times the GPU memory bandwidth compared to G6e instances. By using the higher GPU memory offered by G7e instances, you can run medium-sized models of up to 70B parameters with FP8 precision on a single GPU.
- NVIDIA GPUDirect P2P — For models that are too large to fit into the memory of a single GPU, you can split the model or computations across multiple GPUs. G7e instances reduce the latency of your multi-GPU workloads with support for NVIDIA GPUDirect P2P, which enables direct communication between GPUs over PCIe interconnect. These instances offer the lowest peer to peer latency for GPUs on the same PCIe switch. Additionally, G7e instances offer up to four times the inter-GPU bandwidth compared to L40s GPUs featured in G6e instances, boosting the performance of multi-GPU workloads. These improvements mean you can run inference for larger models across multiple GPUs offering up to 768 GB of GPU memory in a single node.
- Networking — G7e instances offer four times the networking bandwidth compared to G6e instances, which means you can use the instance for small-scale multi-node workloads. Additionally, multi-GPU G7e instances support NVIDIA GPUDirect Remote Direct Memory Access (RDMA) with Elastic Fabric Adapter (EFA), which reduces the latency of remote GPU-to-GPU communication for multi-node workloads. These instance sizes also support NVIDIA GPUDirectStorage with Amazon FSx for Lustre, which increases throughput by up to 1.2 Tbps to the instances compared to G6e instances, which means you can quickly load your models.
EC2 G7e specifications
G7e instances feature up to 8 NVIDIA RTX PRO 6000 Blackwell Server Edition GPUs with up to 768 GB of total GPU memory (96 GB of memory per GPU) and Intel Emerald Rapids processors. They also support up to 192 vCPUs, up to 1,600 Gbps of network bandwidth, up to 2,048 GiB of system memory, and up to 15.2 TB of local NVMe SSD storage.
Here are the specs:
| Instance name |
GPUs | GPU memory (GB) | vCPUs | Memory (GiB) | Storage (TB) | EBS bandwidth (Gbps) | Network bandwidth (Gbps) |
| g7e.2xlarge | 1 | 96 | 8 | 64 | 1.9 x 1 | Up to 5 | 50 |
| g7e.4xlarge | 1 | 96 | 16 | 128 | 1.9 x 1 | 8 | 50 |
| g7e.8xlarge | 1 | 96 | 32 | 256 | 1.9 x 1 | 16 | 100 |
| g7e.12xlarge | 2 | 192 | 48 | 512 | 3.8 x 1 | 25 | 400 |
| g7e.24xlarge | 4 | 384 | 96 | 1024 | 3.8 x 2 | 50 | 800 |
| g7e.48xlarge | 8 | 768 | 192 | 2048 | 3.8 x 4 | 100 | 1600 |
To get started with G7e instances, you can use the AWS Deep Learning AMIs (DLAMI) for your machine learning (ML) workloads. To run instances, you can use AWS Management Console, AWS Command Line Interface (AWS CLI) or AWS SDKs. For a managed experience, you can use G7e instances with Amazon Elastic Container Service (Amazon ECS), Amazon Elastic Kubernetes Service (Amazon EKS). Support for Amazon SageMaker AI is also coming soon.
Now available
Amazon EC2 G7e instances are available today in the US East (N. Virginia) and US East (Ohio) AWS Regions. For Regional availability and a future roadmap, search the instance type in the CloudFormation resources tab of AWS Capabilities by Region.
The instances can be purchased as On-Demand Instances, Savings Plan, and Spot Instances. G7e instances are also available in Dedicated Instances and Dedicated Hosts. To learn more, visit the Amazon EC2 Pricing page.
Give G7e instances a try in the Amazon EC2 console. To learn more, visit the Amazon EC2 G7e instances page and send feedback to AWS re:Post for EC2 or through your usual AWS Support contacts.
— Channy




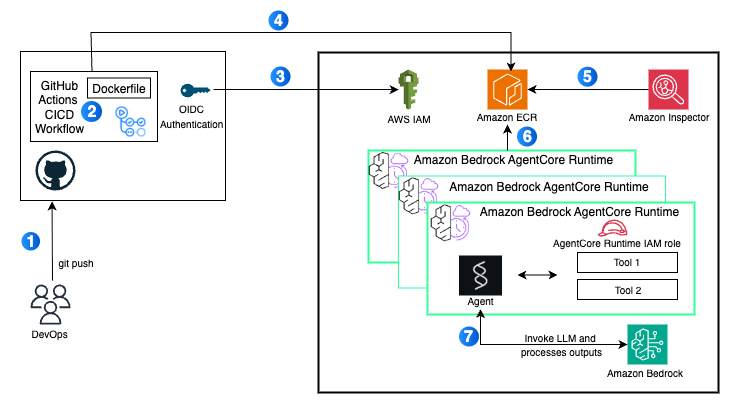
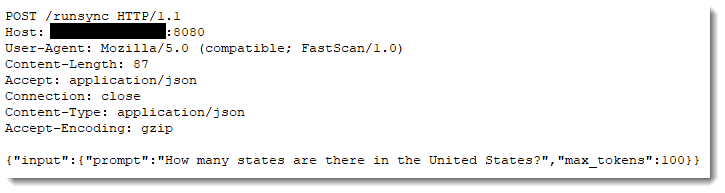
![Battling Cryptojacking, Botnets, and IABs [Guest Diary], (Thu, Jan 15th)](https://www.ironcastle.net/wp-content/uploads/2026/01/status-7.gif)